Abstract
Experimental Results
We evaluate BESO on several challenging goal-conditioned imitation learning benchmarks and compare it to numerous state-of-the-art methods. We show that BESO consistently outperforms all baselines while only using 3 denoising steps. We additionally provide extensive ablation studies and experiments to demonstrate the effectiveness of our method for goal-conditioned behavior generation. See example rollouts below.
GC-Kitchen
GC-Block Push
CALVIN 2 Tasks
CALVIN Hard Tasks
D3IL Align (inside)
D3IL Align (outside)
CALVIN 5 Task Sequences
CALVIN 5 Task Sequences
Real World Experiments
We evaluate BESO on a challenging real world toy kitchen environment with 10 tasks and compare it to the goal conditioned BC baseline.
Move the banana from sink to right stove (BESO)
Move the banana from sink to right stove (GCBC)
Pick up toast ande put it into the sink (BESO)
Pick up toast ande put it into the sink (GCBC)
Open oven (BESO)
Open oven (GCBC)
Move the pot from sink to the right stove (BESO)
Move the pot from sink to the right stove (GCBC)
Pull oven tray (BESO)
Pull oven tray (GCBC)
Failure Cases in Real Robot Experiments
Task: Move the pot from the sink to the right stove. BESO went to the stove instead of the sink, and failed to pickup the pot afterwards.
Task: Pick up the toast and put it into the sink. BESO didn't lift the toast high enough and carried the toaster too.
Classifier-Free Guided Policy
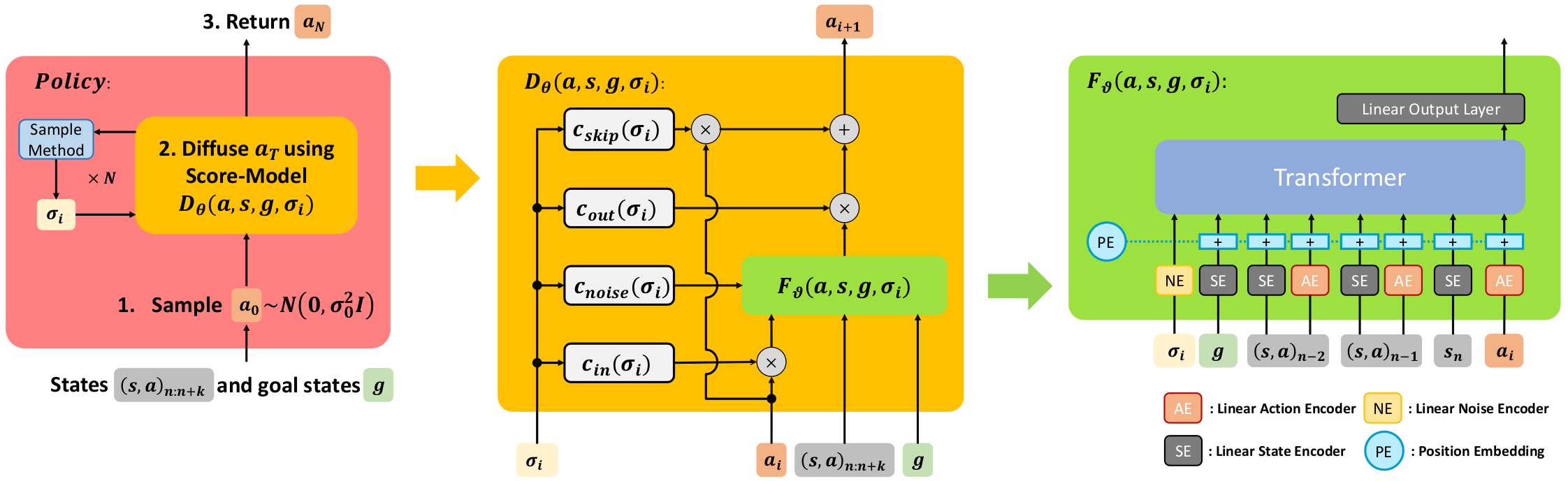
Our experiments showcase the effectiveness Classifier-Free Guidance (CFG) Training of Diffusion Models in simultaneously learning goal-independent and goal-dependent policies. We can compose the gradients at test time to control the amount of goal-guidance we want to apply to the policy. The purpose of this setup is to demonstrate the influence of goal-guidance on the behavior of the policy. By gradually increasing the value of lamda, we can observe how the policy becomes more goal-oriented and achieves a better success rate in accomplishing the desired goals.
Below you can see the performance of CFG-BESO on the kitchen and block push environment. When we set the guidance factor lamda=0, we completely ignore the goal and generate random behavior with a high reward and low result (only gives credit, if a pre-defined goal is solved).
Using BESO in your own project
While BESO was initially designed for goal-conditioned imitation learning (IL), the general idea of using continuous-time diffusion models as a policy representation can be applied to standard (IL) and in hierarchical policies as well. If you are interested in trying out BESO for Behavior Cloning, we build a BC-variant in a fork of the beautiful IL Benchmark Repo: BESO Diffusion Policy.
One of the key advantages of our BESO implementation is the use of a modular continuous-time diffusion model based on the work by Karras et al. 2022. This modular approach allows for greater flexibility in adapting the sampler and adjusting the number of diffusion steps during inference, leading to improved performance. Additionally, our implementation enables fast action diffusion in just three steps.
BibTeX
@inproceedings{
reuss2023goal,
title={Goal Conditioned Imitation Learning using Score-based Diffusion Policies},
author={Reuss, Moritz and Li, Maximilian and Jia, Xiaogang and Lioutikov, Rudolf},
booktitle={Robotics: Science and Systems},
year={2023}
}
Acknowledgements
The work presented here was funded by the German Research Foundation (DFG) – 448648559.
Related Projects
Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals
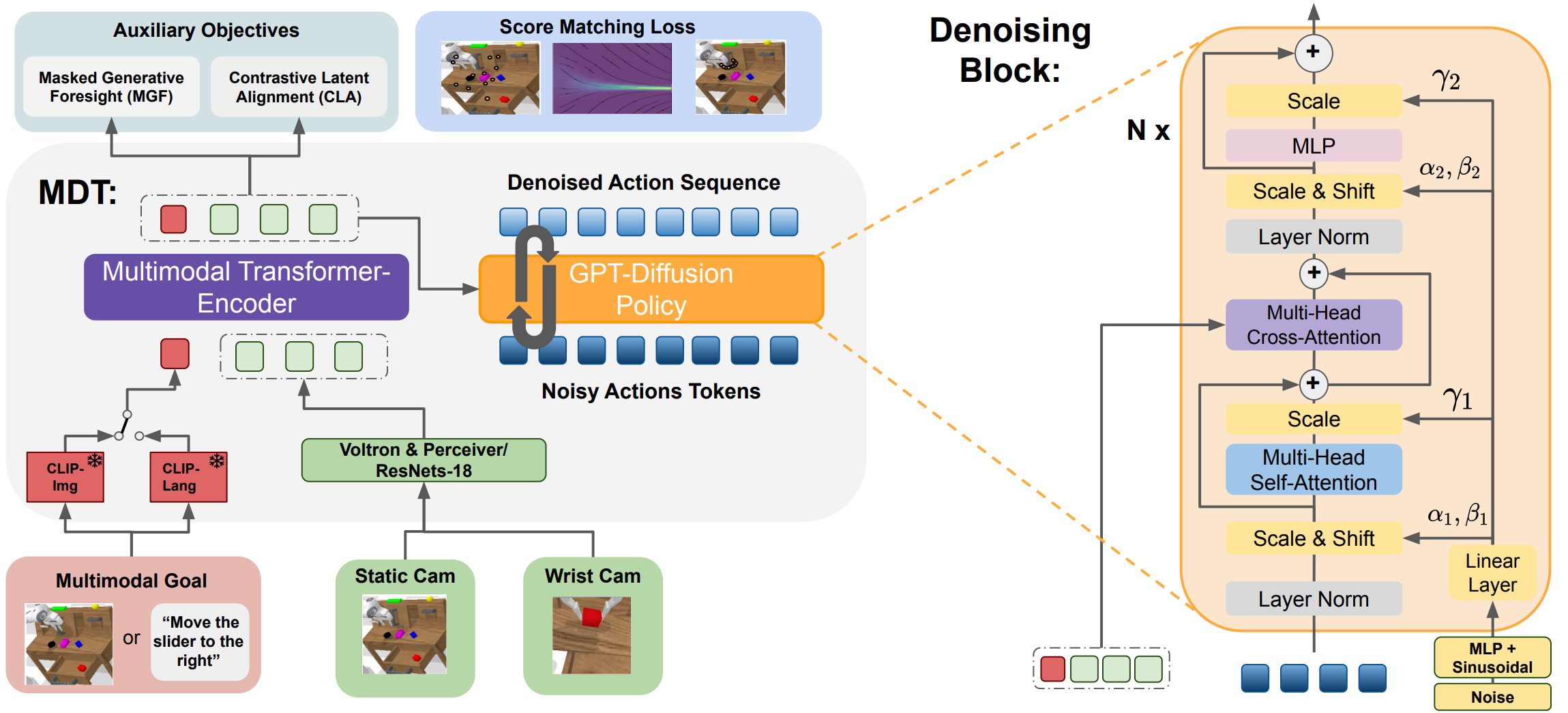
The Multimodal Diffusion Transformer (MDT) is a novel framework that learns versatile behaviors from multimodal goals with minimal language annotations. Leveraging a transformer backbone, MDT aligns image and language-based goal embeddings through two self-supervised objectives, enabling it to tackle long-horizon manipulation tasks. In benchmark tests like CALVIN and LIBERO, MDT outperforms prior methods by 15% while using fewer parameters. Its effectiveness is demonstrated in both simulated and real-world environments, highlighting its potential in settings with sparse language data.
Scaling Robot Policy Learning via Zero-Shot Labeling with Foundation Models
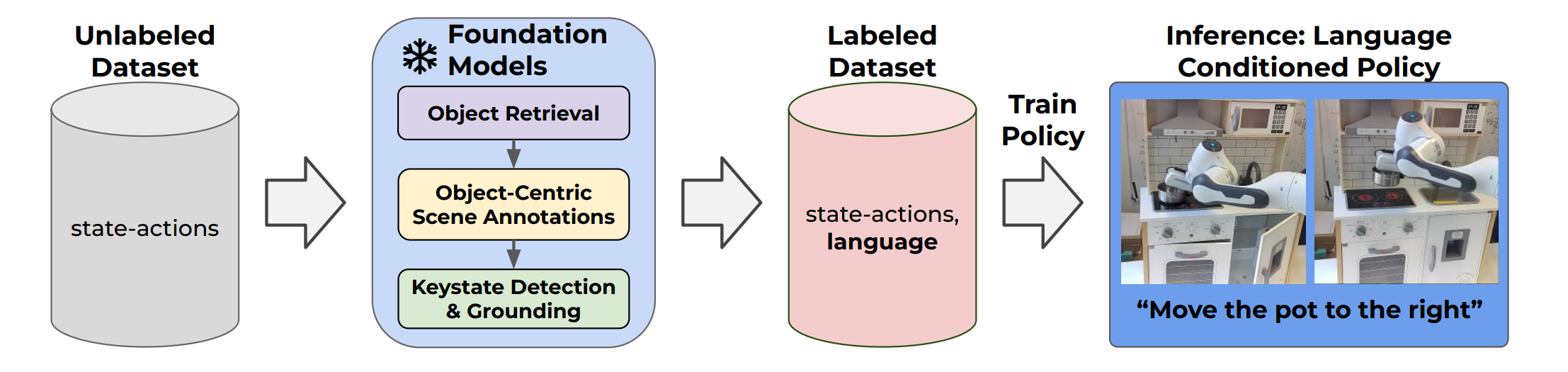
Using pre-trained vision-language models, NILS detects objects, identifies changes, segments tasks, and annotates behavior datasets. Evaluations on the BridgeV2 and kitchen play datasets demonstrate its effectiveness in annotating diverse, unstructured robot demonstrations while addressing the limitations of traditional human labeling methods.